即日起博客关闭基于 Disqus 的评论系统,改用简单的表情投票反馈。如果有文字反馈,可以继续使用下面基于 utteranc.es 的留言框(需要 github 账号),也欢迎直接发送电子邮件留言。
关闭 Disqus 的主要原因是它现在开始显示广告了,因为我一直使用广告屏蔽工具,所以也不太清楚自己博客上是什么时候开始有显示广告的,直到最近它给我推送付费账号的信息我才意识到。仔细思考和权衡了一下各种解决方案,最终还是决定放弃使用 Disqus。
We are drowning in information and starving for knowledge.
欢迎来到 Free Mind ,这是由 pluskid 所维护的 blog ,主要记录一些机器学习、程序设计以及各种技术和非技术的相关内容。如非特别指明,本站的文章遵循 Attribution-ShareAlike Creative Commons 协议。更多文章索引请浏览 Archive, Categories, 和 Tags。 部分文章前后有一定的关联,也可在 Series 中找到索引。早期的博客文章请参见 Free Mind 2009~2012 和 Free Mind 2007~2009。博客内容仅代表个人观点,与雇主无关。
即日起博客关闭基于 Disqus 的评论系统,改用简单的表情投票反馈。如果有文字反馈,可以继续使用下面基于 utteranc.es 的留言框(需要 github 账号),也欢迎直接发送电子邮件留言。
关闭 Disqus 的主要原因是它现在开始显示广告了,因为我一直使用广告屏蔽工具,所以也不太清楚自己博客上是什么时候开始有显示广告的,直到最近它给我推送付费账号的信息我才意识到。仔细思考和权衡了一下各种解决方案,最终还是决定放弃使用 Disqus。
山 忽隐忽现
海市蜃楼是沙漠谎言
天 衔接水面
我的地平线越缩越远
2025 基本上不是在外面旅行,就是在做旅行计划、办签证,或者是在做旅行后的手账、照片和视频整理。用今年的旅行为主题让 Nano Banana Pro 生成了一张封面照片,和 2022 年用 Stable Diffusion 生成的图片相比,可以看到 AI 在这几年是有非常明显的进展的。
不过 AI 的事情之后再聊。简单回顾了一下,发现今年从三月开始,几乎(除去八月)没有哪一个整月是完全待在家里的,伦敦去了三次,日本也跑了两趟,还非常极限地 17 小时飞到新加坡,早上落地晚上直接飞走。整个十二月都在欧洲,很多年来第一次不在家跨年,不得不在公司本上写总结,费了不少劲才把环境设置好。
今年一共读了 24 本书,外加 11 本漫画。其中实体书和电子书的比例大概是 2:1,中文书很多都是在微信阅读上看的电子书,而英文和日文则主要都是实体书。从统计数据上来又是历年最低,主要原因是今年太多时间在外面跑了。
年度最佳图书这里中、英、日各推荐一本,虽然好像也没法达到六星好评。
想说却还没说的 还很多
攒着是因为想写成歌
让人轻轻地唱着 淡淡地记着
就算终于忘了 也值了
第一次造访布鲁克林,虽然有各种文艺小店(印象最深的是文具店由申甲居然提供所有钢笔、墨水试写和橡皮擦试用)和打卡圣地,但是十二月纽约的严寒不停地教育我湾区的冬天那根本不叫冬天,在波士顿生活了许多年也不记得有这么冷,人真是很健忘啊!一直不停地擦鼻涕,都不太能腾出手拍照片。好在晚上李宗盛的演唱会是在室内,一串老歌听得热泪盈眶,驱散了所有的严寒。

今年阅读比较不毛,因为看完了《大剑》全套 27 卷,所以日文阅读量尚可,但若除去漫画,总体数量似乎是近些年最低的,正好简单统计并绘制了一下过去 7 年的阅读数据。
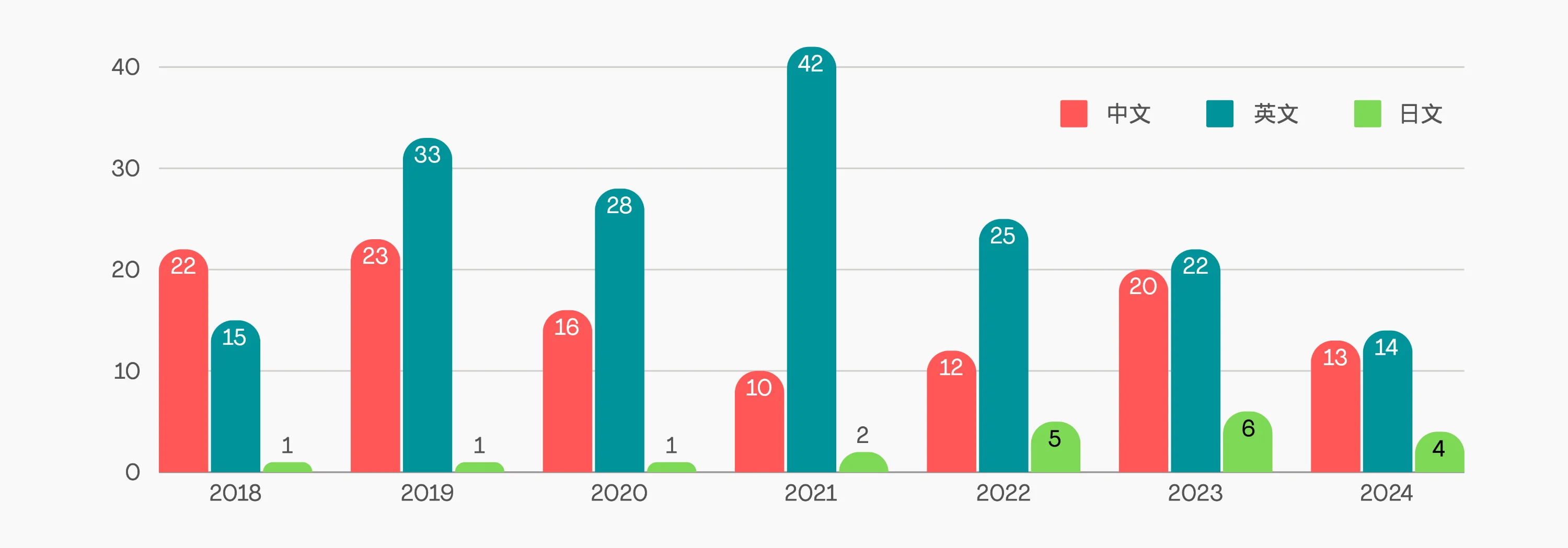
此外今年实体书与电子书的比例正好是 2:1。总之数量下降所以书单和总结的工作量也就减小了!以下大致按评分介绍一下今年的图书。原本觉得今年可能没有六星推荐的图书,但是看了一下往年的六星书,不禁怀疑是不是自己变得更挑剔了,于是对前面几本评分做了一下微调,升级为六星。😛
这是他的青春 留下
留下来的散文诗
从若干年前起开始用“冷门歌手”孙燕姿的歌作为年终总结的标题,一直持续至今,结果今年 AI 孙燕姿突然火遍大江南北,网友用她的声音素材训练出生成模型然后去翻唱各种风格迥异的曲目,一下子扩大了我年终总结用的曲库😅。这里用《父亲写的散文诗》,因为今年回了一趟国见到父母,他们的性格脾气还是老样子,但面容上却突然间多了许多岁月的痕迹——但也不能说是“突然”了,因为签证 + 疫情其实前后耽搁五六年没回去了,所以这次回去非常开心,更开心的是 2023 年终于不再是“宅家的又一年”,去了日本韩国墨西哥,也算知足了。

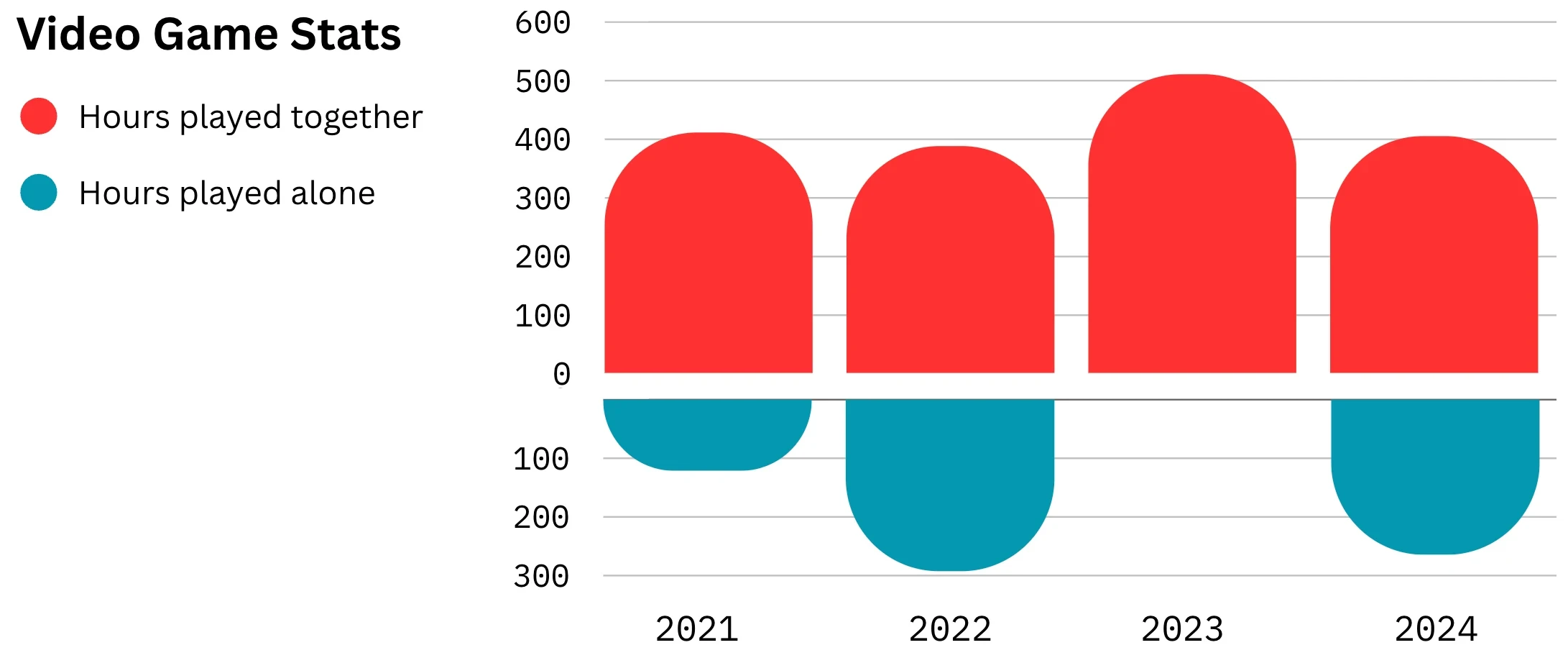
今年通关的游戏总共只有 5 款,相比于去年的 23 款似乎是大幅下降,但考虑到去年是完全宅家,而今年出了好几趟远门,另外从总时长来看,相比于去年的 682 小时,今年的 511 小时也并不算少(这个数字在年末最后几天假期还在因博德之门 3 而持续飞升中)。所以其实今年玩游戏的热情一点也没有减少,幸运的是市面上的好游戏也在持续不断地推出。并且今年这几款通关的作品都是全程与 N 一起玩的。
我个人今年的年度最佳游戏要颁给《境界天火》,感觉给我打开了新世界的大门,体验到了机甲和射击游戏的乐趣;同样让人打开新世界大门体验到以前未曾接触过的游戏类型的游戏是今年 The Game Awards 官方的年度最佳游戏《博德之门 3》,但是鉴于通关还有一段时间,就放到明年的列表上吧。此外《王国之泪》虽然由于上一作过于优秀导致新鲜感没有那么强,但是依旧是做出了非常厉害的创新和超越!

今年很懒,都没有做季度图书总结,整年的书单都放在这里了,正好做一下大致统计,总计读完 57 本书(中文 20,英文 22,日文 15),但是其中有 9 本是漫画,还有不少艺术类书籍,所以总体大概和去年(42 本)差不多。这当中大约三分之一是电子书,特别是最近发现微信读书平台其实各方面都还挺好用的,也能很方便地在电子墨水屏的安卓阅读器上安装使用之后,在上面看了不少中文电子书。
A pen and pencil and paper is nothing if you have nothing to say. Otherwise do pretty watercolors and forget it.
《Reportage Illustration: Visual Journalism》是一本介绍 Reportage Illustration 的书,Reportage Illustration 按照字面意思翻译大概应该叫做“新闻插画”,但也许称作“新闻速写”更恰当一些,它可以归类到 Visual Journalism 下面,基本上是指新闻或者艺术工作人员通过现场作画和记录来报道某一个具体的事件。我最初了解到这本书以及这个行业是在公司的艺术兴趣班的一个叫做 Visual Journalism 的课上,老师带着大家一起去各种不同的场所,例如音乐会、咖啡店的脱口秀表演、户外甚至是一起观看某个著名的视频演讲等,然后让大家通过速写和文字结合的方式对现场体验进行描绘和记录,关键并不是要画出多么漂亮的画,而是要通过速写的方式记录下当时的氛围、声音、色彩、对话、天气等各种感官体验。
整体而言还挺好玩的,虽然和照片甚至录音录像相比通过速写能记录下来的信息量极少,但正因为能记录的内容有限,我们需要舍弃大量东西,反而导致我们记录中的内容是在现场令我们印象最深刻的体验(当然要做好这一点也是需要经过许多训练的)。所以再回去看自己当时的涂鸦时可能更容易重现现场的感触和记忆。然而这针对“个人”而言很合理,但是如果读者不是未来的自己,而是作为真正的新闻报道那样的形式给呈现给他人的话,看到杂乱的涂鸦和速记时能够重现的氛围体验有多少就很难讲了。所以我读这本书的一个疑问其实是这个行业究竟是如何存在的。