上一次我们讨论了具有 Q-线性收敛性的普通的 gradient descent 方法,今天我们要介绍一种收敛速度更快的算法:Newton Method(或者叫 Newton’s Method)。
可能大家知道有两个算法同时叫做牛顿法,一个是用迭代法来求方程的根的方法,另一个是 optimization 里的牛顿法,实际上这两者是同一个方法,或者同一个思想。今天我们要讲的是后者,但是由于前者比较简单,并且有有趣的故事,所以我们还是从前者讲起。故事开始于雷神之锤 III 竞技场里的一段神秘的快速求平方根倒数的代码:
- float Q_rsqrt( float number )
- {
- long i;
- float x2, y;
- const float threehalfs = 1.5F;
-
- x2 = number * 0.5F;
- y = number;
- i = * ( long * ) &y;
- i = 0x5f3759df - ( i >> 1 );
- y = * ( float * ) &i;
- y = y * ( threehalfs - ( x2 * y * y ) );
- // y = y * ( threehalfs - ( x2 * y * y ) );
- return y;
- }
据称比直接计算要快了 4 倍。其中的两次迭代(第二步迭代被注释掉了)就是用的牛顿法来求解方程 ,也就是 的根。牛顿法的思想其实很简单,给定一个初始点 ,使用在该点处的切线来近似函数,然后寻找切线的根作为一次迭代。比如对于这个例子,令 ,给定初始点 ,在该点处的导数是 ,由此可以得到该处的切线为 ,求解 得到
正是代码中的迭代。当然代码的重点其实不在这里,而在
0x5f3759df 这个奇怪的 magic
number,用于得到一个好的初始点。这个神奇的数字到底是谁发现的,根据
wikipedia 上的说法似乎至今还没有定论。xkcd 还为此画了一条漫画,讽刺说每次我们惊奇地发现工业界里不知道哪个无名人士写出了
0x5f3759df
之类的神奇数字,背后都有成千上万的其他无名人士我们无从知晓,说不定他们中的某一个人已经解决了
P=NP
的问题,但是那人却还在调某个自动打蛋器的代码所以我们至今仍无知晓。:D
回到我们今天的话题,从这段代码中我们可以看到两点:
- 牛顿法收敛非常快,对于精度要求不是特别高的情况,比如上面的图形学相关的计算中,甚至只用了一次计算迭代。
- 另一方面,初始值的选取非常重要,我们接下去将会看到,初始值选得不好有可能会直接导致算法不收敛。
轶事讲完之后,正式回到我们的 optimization 的话题。回忆一下上一次我们提到迭代优化算法许多都可以理解为通过不动点法寻找 的根,如果我们套用刚才提到的牛顿法,可以在每一次迭代的时候对 进行一阶近似来寻找其零点。注意到对 gradient 进行一阶近似其实就是对原函数 进行二阶近似,由此我们得到了 optimization 里的牛顿法。
具体来说,从初始点 开始迭代,每一次迭代,在当前位置对 进行二阶近似,在 点处进行泰勒展开并丢掉二次以上的项,得到:
是一个二次函数,直接令 可以解得:
这就是牛顿法的基本迭代步骤。这实际上是上一次介绍的 general 迭代框架的一个特殊情况:当 的时候。但是这个特殊的 的取法使得算法的收敛性有了质的飞越。具体来说,现在我们有了 Q-二次收敛性。一个数列 满足 Q-二次收敛是指 且
虽然听起来只有二次,但是实际上是非常非常快的,比如如下的数列
就是二次收敛的,, , ,粗略地讲,如果一个数列按 Q-二次收敛,那么没一次迭代我们可以使得小数点后的精确位数翻一倍。当然牛顿法并不是万金油,首先需要注意的一点是,牛顿法并不能总是保证收敛,当然,在上一次我们分析 gradient descent 的时候也是做了许多假设,不过牛顿法在这方面更加娇贵:首先函数的性质要好,并且初始解必须在离最优解比较近的地方才能保证收敛,而这个邻域可以是多大则依赖于一堆通常无法计算或估计的常数。
实际上,如果 Hessian 在当前的 处是不可逆的,那么 (eq: 1) 本身就是没法计算的。如果 Hessian 是可逆的,并且是 (semi)definite 的话,则
也就是说牛顿方向和 gradient 的负方向呈锐角,是一个下降(或者非增)方向。但是如果 Hessian 不是 (semi)definite 的话,就无法保证这一点了。另外,所谓下降方向的意思只是说沿着该方向移动足够小的步长可以保证函数是下降(非增)的,但是这里使用固定步长 1 却不能保证这一点(但是步长 1 又是证明二次收敛性所需要的)。
因此有一种牛顿法的变种,叫做 Damped Newton Method,就是在计算出牛顿方向之后,再用 backtracking 的方式做一次 linesearch。Backtracking linesearch 比之前介绍的基于 Wolfe’s Condition 的 linesearch 要简单,它有两个参数 和 。简而言之 backtrack linesearch 从初始步长 1 开始,每一次迭代将步长乘以 ,直到满足如下条件为止:
这里的 是 linesearch 的方向。我们从《Convex Optimization》盗一张图来说明一下。
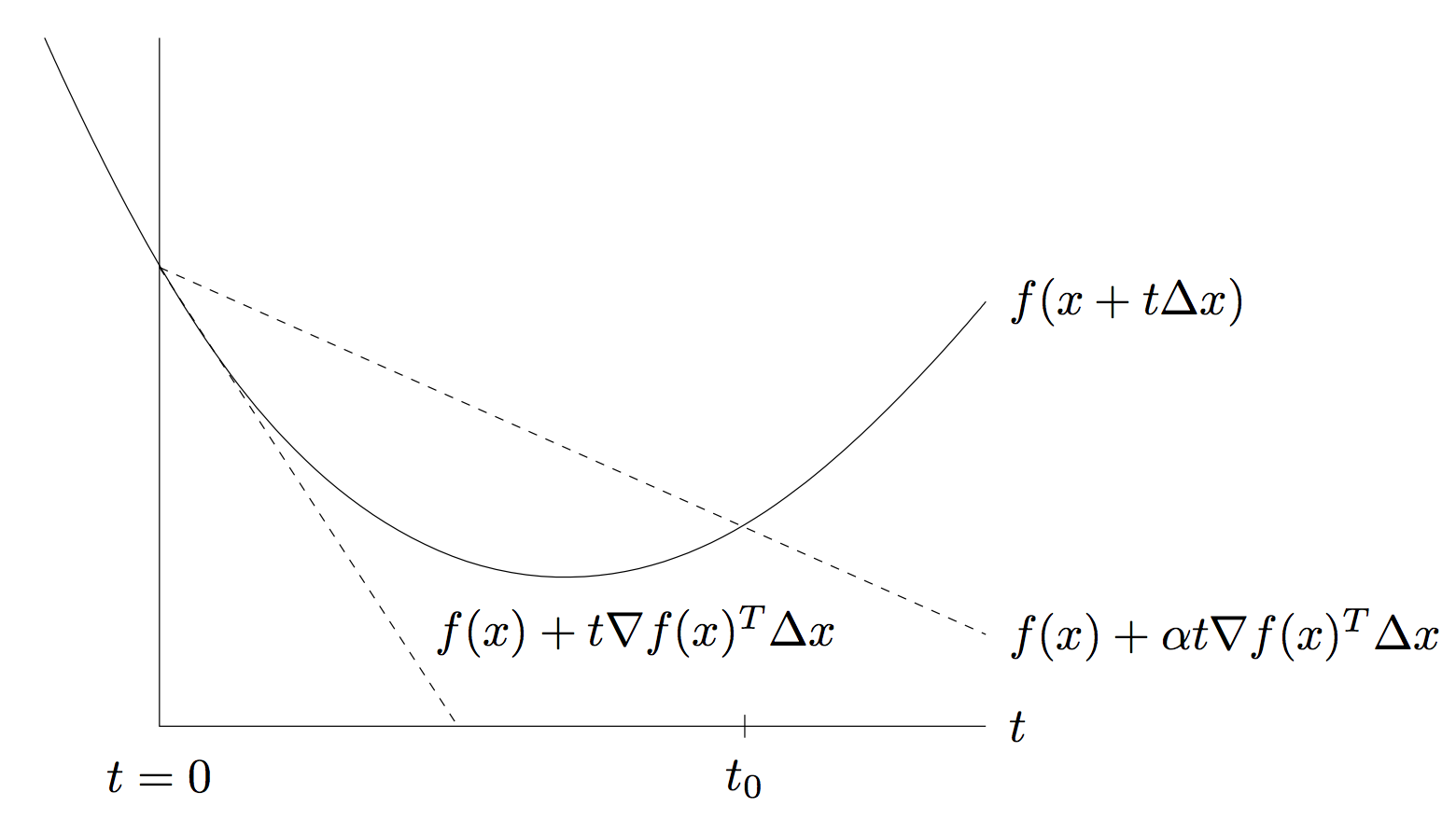
由于 是下降方向,所以对于足够小的 ,我们有
所以 linesearch 可以保证停止,从图中来看,实际上就是寻找 中的一个步长, 的大小决定了我们期望的下降量,比如极端情况 则是任何非增的步长都会接受。以下是 julia 代码:
- function linesearch{T}(p::OptimizationProblem, x::Vector{T},
- d::Vector{T})
- t = convert(T, 1)
- fx = objval(p, x)
- dfx = gradient(p, x)
- while objval(p, x + t*d) > fx + alpha * t * dot(dfx, d)
- t = beta * t
- end
- return t
- end

增加了 linesearch 之后的 Damped Newton Method 有一个比较好的性质就是当迭代进入离最优解足够近的一个收敛区域之后,linesearch 一定会返回默认步长 1,从而进入 pure Newton Method 的 Q-二次收敛的阶段。具体细节和证明可以参考《Convex Optimization》第 9 章的 Newton Method 一节。
这里我们给一个简单的一维情况下的例子,最小化 ,这是一个 convex 函数,其最小值在 处达到。这里我们给出 Newton Method、Damped Newton Method 和普通的 Gradient Descent 的结果。

大约在 这个区间内是该函数的 Newton 收敛区间,可以看到当我们选取初始值为 1.09 之后 Newton Method 直接不收敛了。但是 Damped Newton Method 则表现良好,并且在第三个例子中初始点离最优解比较远的情况,二次收敛的速度优势就体现出来了。
接下来我们可以再看一个更加实际一点的例子,也就是我们上一次介绍过的 Logistic Regression 的情况。为了将牛顿法用在 Logistic Regression 上,我们需要求目标函数的 Hessian,为了方便起见我再把目标函数搬过来:
上一次我们已经求过其 gradient 为
接下来很容易算出其 Hessian 矩阵为
然后直接套用我们刚才说的 Damped Newton Method,目标函数在 USPS 数据集上的收敛结果如图所示,可以和上一次的 Gradient Descent + Wolfe Linesearch 进行对比。

可以看到 Newton Method 十来次迭代就收敛了。不过这里有一个细节需要注意,就是我们在上一次的例子中给出用 gradient descent 来优化 Logistic Regression 的目标函数的时候,直接丢掉了 regularizer (),而这里则必须要加上 regularizer,因为否者计算出来的 Hessian 会接近 singular,在求逆(或者说解线性方程组)计算 (eq: 1) 的时候直接爆炸掉了,没法收敛到一个好的结果。图中的结果对应取 的情况。
实际上这里暴露出来的一个问题也确实是牛顿法在实际中经常碰到的一个问题:Hessian 矩阵 singular 或者是接近 singular 的情况。通常的做法是在对角线上加正数,在这里其实就对应于目标函数里的 regularizer 。上一次的 Gradient Descent 算法中我们也讨论过,加 regularizer 可以减小 condition number,从而改善收敛速度。但是需要注意的是并不是 regularizer 加得越厉害越好。因为加 regularizer 的原因不仅是出于优化来考虑,而且还有 learning theory 方面的 generalization performance 方面的考虑,从后者的角度来说 regularizer (系数)的大小是有一个合适的值范围的,太大太小都不好(实际中一般通过 cross validation 来选取 regularizer 系数)。因为我们的最终目的是做 learning 和 prediction,如果一切只是为了优化方便,那么只要把目标函数变成一个 constant function 之类的,那么任何优化算法都可以一步收敛,但是却没有什么用处。
除了加 regularizer 之外,解决 Newton Method 的 near-singular Hessian 问题的方法还有其他很多,比如并不精确计算 Hessian,而是用一个性质良好的正定矩阵去近似估计当前的 Hessian,这一类方法通常被称为 Quasi-Newton Method,比如比较有名的 L-BFGS 算法,今天就不在这里细讲了。
不过 Quasi-Newton Method 的更重要的 motivation 其实是 Newton Method 的另一个严重的弱点:计算量。虽然 Newton Method 收敛快,只需要很少次的迭代,但是每一步迭代的计算量却比普通的 Gradient Descent 要大很多:Gradient Descent 只要计算一个 维 Gradient 向量即可,Newton Method 不仅要计算 Hessian 矩阵( 维),而且要对该矩阵求逆(或者是解线性方程组)——对于通常的 dense 矩阵,这是一个复杂度为 的操作。
对于所谓的 big data 问题,Newton Method 通常难以应用。比如刚才的 Logistic Regression 的例子,如果数据点的个数非常多,由于计算 Hessian 每次都要遍历一遍所有数据并计算外积 ,这会在每一次迭代都花掉很多时间。更严重的是,如果数据的维度非常高,且不说后面的求逆操作,即使 Hessian 矩阵本身的求解甚至存储都会出现问题。有时候碰到的情况是连 Newton Method 迭代一次的计算量都承担不起,所以在大规模机器学习或者 general 的大规模优化问题中,简单的一阶(只需要用到 gradient 信息)算法得到了更多的关注。以后我们还会看到,不仅是 Hessian,连 Gradient 向量的计算都非常 costly 的情况,以及对应提出的 Stochastic Gradient Descent 系的算法。
Comments
终于更新了!
Logistic regression的Newton method不是有个名字叫IRLS。Boyd那书的附录里有蛮多对付Hessian矩阵是Sparse或者有特殊结构的方法
应该不是吧?我 google 了一下这个 IRLS,虽然没仔细看,但是这个似乎是做回归分析的,Logistic Regression 是做分类,目标函数差别好大的,也不是 square loss。
wiki上那个不是logistic regression的IRLS。PRML 4.3 节, MLAPP 8.3.4 节。我没记错的话,logistic regression的Newton有一些trick在,最后的迭代也很简单,所以给它的Newton方法起了个名字叫IRLS
我看了一下好像是因为计算牛顿方向的那一步可以写成 weighted least square 的形式所以这么叫,但是这样只是形式上吧?因为 least square 求解其实也是解 linear system 啊,计算上好像并没有什么不一样。
呃,是的。看来有点记残了。。。。
不知道怎么回事好像博客之前内容被回滚了一下,这篇文章消失了好久的样子……
是,ESL也是这样描述的,之所以叫IRLS本质就是为了避免inversion,采用LS求解来替代。然而其实也有直接求逆的,例如使用conjugate gradient等数值方法
赞,没注意看过附录!
其实Boyd讲第9章之前先用一整节的课讲了附录C~
暴露了我没看完课程视频……
请问一下课程是?
应该是 openEdX 的 stanford 那边的 CVX101,https://class.stanford.edu/... 现在已经结束了。
我瞄了一下你更新的代码,于是想要求问你的julia语言是通过什么方式学习的?或者是编程的结构是在哪里学习的
比如我看到
type DemoProblem <: OptimizationProblem
end
之后去看了一下 type.jl 发现这种方式我没有想到过
有什么julia的教程顺便将这种面向对象的方式也讲了么?
julia 似乎没有什么书,好像官方的 manual 也不错,虽然语言发展很快导致文档有点老旧了,说实话我也没有时间一直 track 它的最新 development。至于编程范式之类的这个大概是所有语言都差不多通用的?多看看别人的代码自己多尝试写点代码的话应该就会慢慢熟悉了?
i = 0x5f3759df - ( i >> 1 );
这样操作的意义是为了使得迭代的初始值 x0 满足 1/3C < x0^2 < 5/3C,假设C是输入的正的 float 浮点数。而 1/3C < x0^2 < 5/3C 又是牛顿迭代函数 x_{n+1} = f(x_n) 里面 f 成为压缩映射的充分条件。一旦对于全部 float 浮点数,f 的导数的绝对值小于1,根据拉格朗日微分中值定理,f 成为压缩映射。再根据巴拿赫不动点定理,对于所有 float 浮点数,f 存在唯一的不动点,迭代必收敛到不动点。
我试了一下,对于所有的 float 浮点数,从最小的正数 FLT_EPSILON,到最大的 float 浮点数 FLT_MAX, f 都会成为压缩映射,迭代序列收敛到唯一的不动点,并且收敛精度有保证。
昨天想明白这个道理的,来和博主分享一下~
哈哈,多谢分享!就是说根据 float 在内存里的存储方式直接当做 long 来看待,做一个位移操作在用那个神奇的数字减一下就能把它放到 (1/3C, 5/3C) 这个区间里去了?真是好 tricky 啊。
你好,这个问题我很早以前就在研究了,这其中的道理没有你想的这么简单。实际上这个求根式倒数的这个过程中牛顿迭代本身就是压缩映射的,只要初始值在足够接近真实值,它必定收敛。关键问题在于收敛的速度。这个值的选取直接关系到敛速的快慢,而在当时,对一个游戏来说,运算时间就是生命。。。注意到牛顿迭代并不是严格单调递减的,根据函数的凸性以及初始值在真实值的哪一侧,第一次迭代可能会有值增加的可能。但是,这个算法要求的是一次迭代就能算出可用的结果,这就要求你一开始的取值不应该过多的大于真实值(或者说存在一个margin),准确地说,是迭代以后的误差不能大于迭代之前的误差。所以,一开始,你如果仅仅以尽可能的减小误差为原则来取初始值就会有问题,因为这样会导致某些点在margin以外。。。正确的做法是一开始就把迭代的效应考虑进去,这就是magic number的来源。。。
格式好像有问题,放在图片里面。
嗯,你说的没错,我看了wiki,其实这一步确实是在找足够接近真实值的点,魔数的大小决定这个点的位置。也就是那个小sigma的值,理论上算出的小sigma是0.0430357,我做过图,正好是f(x)=x-sigma通过g(x)=log(x+1)的“中间”位置(魔数取得太大或太小都会导致没有交点,甚至不收敛),但是,这个值虽然收敛,但是不是最好的值。我上面说的就是,你把这个值向前push一个很小的距离,收敛效果会更好,但是这个距离有个极限,超过以后,效果就会变差。。。具体原因是,对于同等的误差大小,我们更希望估算点小于真实值,所以我们希望有尽可能多的点被低估而不是高估,同时又希望总体误差不能太大。这就是为什么当小sigma=0.0430357结果并不是最优的,因为你可以通过提升小sigma来使得一部分点被低估,同时这种提升获得的增益是正的。。。这个提升的准确值目前无人可以计算出来,所以包括魔数在内的以及那篇论文提到的都是近似计算得到的值。求解这个优化问题涉及解超越方程。。。
谢谢你说的信息,很有意思。我也去看了下wiki,确实是你说的那样,那个魔数对应的sigma=0.0450466。也就是说要找到最好的魔数只能试了,好在这个范围确实很小。