本文是 Machine Learning and Optimization
系列的第一篇。我会尝试介绍一些机器学习中的常用的优化算法和相关的基本理论,并结合具体的机器学习模型的例子进行简单分析和示例。系列相关的示例代码会全部放在
github/MLOpt.jl
上。此外由于我挖了太多的“系列”坑了连自己都记不住了,于是专门做了一个 Series
页面将这些坑搜集起来,并且每个系列做一个自己的简要页面并列出系列里的文章,方便索引。此外每篇文章如果属于某一个系列,在文章右边会有系列链接。Optimization
一直是 Machine Learning 里的一个重要部分,关于试图写本系列的介绍文章的
motivation,详见 Machine Learning and
Optimization 的系列主页,下面直接进入正文。
首先考虑最简单的无约束的光滑函数的优化问题,最小化
f:Rd→R,并假设
f
是可导的。此时如果
x∗
是
f
的一个 minimizer
的话,必须要满足什么样的条件呢?但凡是学过微积分的同学应该都会想到导数等于零这个条件。如若不然,假设
∇f=0,考虑
f
在
x∗
处的一阶近似:
f(x∗+v)=f(x∗)+⟨∇f,v⟩+o(∥v∥)
令
v=−t∇f,当正数
t
足够小时,
f(x∗−t∇f)=f(x∗)−t∥∇f∥2+o(t)<f(x∗)
因此
x∗
不能是(局部)minimizer。当
f
是 convex 的时候,这个条件也能保证
x∗
是 global minimizer。但是 general
的情况下这只是一个必要条件,x∗
有可能只是一个局部 minimizer 而非全局最优,或者是一个 local maximizer
或者甚至什么都不是。但是在实际问题中有时候就是会碰到非 convex
又没有太多其他结构可以利用的情况,没有办法有效地找到全局最优解,所以只能找一个
local minimizer 或者只是一个
∇f=0
的点,通常称为 stationary point。例如
f(x)=x3
在
x=0
处就是一个 stationary point。
寻找
f
的 stationary point 其实就是找方程
∇f(x)=0
的解的问题,所以 optimization
的问题和解方程的问题经常都可以互相转化。一个最基本的算法就是 gradient
descent,它是一个迭代的算法,通过依次地生成点
{xk}
逐渐接近 stationary point
x∗。它的迭代公式是
xk+1=xk−tkAk∇f(xk)(1)
其中
tk>0,Ak≻0
是一个正定矩阵,根据
tk
和
Ak
的取法不同会产生出各种各样的变种算法。首先可以注意到的一点是,该算法如其名,根据当前的
gradient 来决定一个 descent 的方向进行移动。根据
f
在
xk
处的一阶近似,如果步长
∥xk+1−xk∥
足够小的话,我们可以保证每一步迭代
f
的值是减小的,而到达 stationary point 的时候迭代将会停止。
当
f
下有界的时候,单调递减的迭代可以保证收敛到一个极限,但是这样还不能保证找到
stationary point:首先收敛的极限可能并不是我们所期望的那一个,其次函数值
f(x)
的收敛也并不一定保证
x
的收敛。
如果想要保证收敛性,我们必须对
f
做一些进一步的假设或限制,针对不同的
tk
和
Ak
的取法也会有不同的结论。注意到
x∗
是迭代公式
(eq:
1) 的一个不动点:
x∗=x∗−tA∇f(x∗)
简单起见,我们考虑
A=I,以及固定
t
为常数的情况,假设
f
二阶可导并且其 Hessian 满足
lI⪯H(x)⪯LI,其中
0<l≤L。此时我们有
∥xk+1−x∗∥2=∥xk−t∇f(xk)−x∗∥2=∥xk−x∗∥2−2t⟨xk−x∗,∇f(xk)⟩+t2∥∇f(xk)∥2=∥xk−x∗∥2−2t⟨xk−x∗,∇f(xk)−∇f(x∗)⟩+t2∥∇f(xk)−∇f(x∗)∥2=∥xk−x∗∥2−2t⟨xk−x∗,H(ξ)(xk−x∗)⟩+t2∥H(ξ)(xk−x∗)∥2≤(1+t2L2−2tl)∥xk−x∗∥2
其中
ξ
是根据中值定理中存在的一点。只要
1+t2L2−2tl<1,亦即
t<2l/L2,就能保证
k→∞lim∥xk−x∗∥∥xk+1−x∗∥≤1+t2L2−2tl<1
此时我们能得到所谓的
Q-线性收敛。当然这个算法实际中比较难严格地应用,一方面要估计合理的
l
和
L
可能会比较困难,另一方面可能要优化的函数本身并不满足这里的
assumption。实际上,我们这里的 assumption 还是很强的,首先
H⪰lI
实际上说 Hessian 是正定的,因此我们已经能保证
f
是 convex 的了,更确切地说,它保证了
f
的 strong convexity,此时 stationary point
x∗
如果存在的话,就一定是 global
minimizer。此外,H⪯LI
的条件可以理解为在说 gradient 的 Lipschitz 连续性。
1
定义 1(Strongly Convex
Functions). 当
f
满足
f(y)≥f(x)+⟨∇f(x),y−x⟩+2α∥y−x∥2
时,称
f
为
α-strongly
convex 函数,其中参数
α>0。当
α=0
时退回到普通的 convex 函数的定义。
直观来讲,convex
性质是指函数曲线位于该点处的切线,也就是线性近似之上,而 strongly convex
则进一步要求位于该处的一个二次函数上方,也就是说要求函数不要太“平坦”而是可以保证有一定的“向上弯曲”的趋势。当然这是一个很强的
assumption,但是同时也是非常重要的 assumption。比如我们都知道如果函数
f
是 convex 的,那么我们可以保证
∇f(x)=0
的点将是一个 global
minimizer,但是在实际的数值计算中,我们很少能直接求解
∇f(x)=0
这个方程,而是需要通过一些迭代的算法来得到一个近似的估计,比如得到一个
x∗
使得
∥∇f(x∗)∥<ϵ,但是仅仅靠
convex 性质并不能保证在这种情况下得到的点
x∗
会是一个比较好的 global minimizer 的近似点。比如
f
在 global minimizer
周围是非常平坦的情况的话,我们有可能会找到一个很远的点但是起 gradient 的
norm 非常小。此时如果我们有 strongly convexity
的话,就能对情况做一些控制,考虑 strongly convex function 的定义式,令
y=x∗
是 global minimizer,而
x=x∗
为我们得到的近似解,于是
f(x∗)≥f(x∗)−⟨∇f(x∗),x∗−x∗⟩+2α∥x∗−x∗∥2≥f(x∗)−∥∇f(x∗)∥∥x∗−x∗∥+2α∥x∗−x∗∥2≥f(x∗)−ϵ∥x∗−x∗∥+2α∥x∗−x∗∥2
由于
f(x∗)≤f(x∗),所以
2α∥x∗−x∗∥2−ϵ∥x∗−x∗∥≤f(x∗)−f(x∗)≤0
得到
∥x∗−x∗∥≤α2ϵ
也就是说通过求方程
∇f(x)=0
的更好的
ϵ
近似,我们可以保证得到原优化问题的更好的近似。当然,这个 bound
的好坏也要取决于 strongly convex 性质中的常数
α
的大小。
再回到迭代优化算法上,除了我们这里提到固定
tk
为常数的情况外,另外一种比较常见的算法是用 line search 来找最优的
tk:就是在确定了前进方向
−Ak∇f(xk)
之后,令
qk(t)=f(xk−tAk∇f(xk)),然后通过最小化一元函数
qk(t)
来得到
tk=argminqk(t),因为是沿着确定的方向最小化,所以又叫做
line search。通常即使原来的函数
f
比较复杂,对应的
qk(t)
可能会变得很简单或者甚至有 closed form
minimizer。直观上来看这种算法要更加 aggressive
一点,不过从收敛性的角度来说,并没有比固定
tk
的算法有本质上的区别,在
∇f
是 Lipschitz
连续的情况下可以证明收敛性,但是如果要保证收敛速度,必须像上面那样做进一步的假设,可以得到类似的线性收敛速度。具体证明可以参考例如《Numerical
Optimization: Theoretical and Practical Aspects》的第 2.5
小节或者《Convex
Optimization》的 9.3.1 节。
这里我们不妨做一个小结:刚才我们所提到的迭代优化算法,在每一次的迭代中通过将原优化问题分解为两个较为简单的优化问题来逐步逼近最优解:
- 寻找局部最优方向,由于是在局部操作,根据函数的光滑性或者其他一些预先知道的结构信息,我们可以对函数进行局部近似,从而将问题简化。最常用的近似就是泰勒展开,其中各种
gradient descent
方法中主要用一阶泰勒展开,而使用二阶展开则可以得到牛顿法,还有最近机器学习中比较多见的
Proximal Method
则是将目标函数分解成简单的和复杂的部分,简单的部分保持原样而只对复杂的部分进行泰勒展开近似。f
在
xk
处的一阶展开为
fˉ(x)=f(xk)+⟨x−xk,∇f(xk)⟩,此时寻找局部最优移动方向则对应优化问题
vminfˉ(xk+v),s.t.∥v∥≤δ
其中
δ
是用于将搜索限制在一个局部邻域里的,因为泰勒展开近似只能保证在局部有效。而上面这个问题中的目标函数关于
v
是线性的,所以非常容易优化。如果
∥v∥
中的 norm 是 Euclidean norm,那么我们立即得到最优解为
v=−∇f(xk),也就是
gradient 的反方向。如果我们取
ℓ1-norm,那么最优解将会对于
∇f(xk)
这个向量的绝对值最大的那个坐标轴的方向(或其反方向),如果最大绝对值的方向不唯一的话可以任取一个,这可以看成是
Coordinate Descent 算法的一种解释。
- 寻找最优步长,在 exact line search 中我们是将问题化简到了最小化
qk(t)
这个一元函数的问题上。如果
qk(t)
的形式简单通常可以做 exact line
search;复杂的情况则通常可以通过进一步的数值迭代算法来得到一个近似的步长,叫做
inexact line
search,这样通常会让这一步计算量变得很大,因此也有许多其他算法来寻找一个“合理”的步长,而不一定要找到(近似)最优的步长,常见有诸如
Wolfe’s Condition、Armijo Rule 之类的。
下面我们来看两个机器学习中的例子,一个是 Linear Regression,另一个是
Logistic Regression。在 Linear Regression 中,我们得到训练数据
{xi,yi}i=1N⊂Rp×R,目标函数如下:
wmin{L(w)=21i=1∑N(yi−⟨w,xi⟩)2+21λ∥w∥2}
写成矩阵的形式(y
为列向量,X
矩阵的行对应数据点)是
wmin{L(w)=21∥y−Xw∥2+21λ∥w∥2}
其中带
λ
系数的那一项是 regularizer,这种带
ℓ2-norm
的 regularizer 的 linear regression 通常也被称为 ridge regression。从
Learning Theory 的角度来说,regularizer 是用于帮助提升模型的
generalization 能力。从数值计算的角度来说,加 regularizer 有助于处理 condition
number 不好的情况下矩阵求逆很困难的问题:因为目标函数是 quadratic
的,所以实际上是有解析解的,求导并令导数等于零即可得到最优解为:
w∗=(XTX+λI)−1XTy
要 evaluate
这个解,我们通常并不直接求矩阵的逆,而是通过解线性方程组的方式(例如高斯消元法)来计算。考虑没有
regularizer 也就是
λ=0
的情况,如果矩阵
XTX
的 condition number 很大的话,解线性方程组就会在数值上相当不稳定,而这个
regularizer 的引入则可以改善 condition number。
既然可以直接通过解线性方程的方式来得到最优解为什么还要用麻烦的
gradient descent
来优化呢?因为剧本就是这么写的啊其实反过来看通过 gradient
descent 或者其他的迭代优化算法来求解对应的 quadratic
目标函数也是另一种解线性方程组的算法:不同的算法有不同的特点,有的时候在特殊的场合下会很有优势。例如如果数据矩阵是非常稀疏的时候,也许高斯消元法中的行的加减操作会产生一些比较
dense
的中间矩阵造成存储和计算困难,但是迭代优化由于只会用稀疏矩阵来进行乘法操作,所以开销可能会相对较小一些。
当然使用迭代优化的算法,condition number
太大仍然会导致问题:它会拖慢迭代的收敛速度,而 regularizer
从优化的角度来看,实际上是将目标函数变成
λ-strongly
convex 的了。首先让我们来看看目标函数对参数
w
的 gradient:
∇L(wk)=XT(Xwk−y)+λwk=(XTX+λI)wk−XTy
我们考虑沿着 gradient 的反方向移动的情况,由于我们可以直接计算出
L(w)
的 Hessian 为
XTX+λI,我们可以直接套用本文一开始的分析方法选择一个固定的
tk
来得到 Q-线性收敛。不过这里由于 quadratic function
形式简单我们可以直接用 exact line search。方便起见,我们记
Q=XTX+λI,
b=−XTy,
c=1/2∥y∥2,则
L(w)∇L(w)qk(t)=21wTQw+bTw+c=Qw+b=L(wk−t∇L(wk))
注意到
qk(t)
是关于
t
的一个二次函数,对
t
求导得到
qk′(t)=t∇L(wk)TQ∇L(wk)−∇L(wk)T(Qwk+b)=t∇L(wk)TQ∇L(wk)−∇L(wk)T∇L(wk)
于是最优解为
tk=∇L(wk)TQ∇L(wk)∇L(wk)T∇L(wk)
带入 gradient descent 的迭代公式,我们可以计算出
L(wk)−L(w∗)L(wk+1)−L(w∗)=1−L(wk)−L(w∗)t∇L(wk)T∇L(wk)−1/2t2∇L(wk)TQ∇L(wk)=1−L(wk)−L(w∗)21∇L(wk)TQ∇L(wk)(∇L(wk)T∇L(wk))2=1−21wkTQwk+bTw+21bTQ−1b21∇L(wk)TQ∇L(wk)(∇L(wk)T∇L(wk))2=1−∇L(wk)TQ∇L(wk)∇L(wk)TQ−1∇L(wk)(∇L(wk)T∇L(wk))2
根据 Kantorovich
不等式,可以得到
L(wk)−L(w∗)L(wk+1)−L(w∗)≤1−(l+L)24lL
其中
l
和
L
是矩阵
Q
的最小和最大的特征值。根据 condition number
κ(Q)
的定义
κ(Q)=L/l,我们可以进一步得到
L(wk)−L(w∗)L(wk+1)−L(w∗)≤(1+κ(Q)1−κ(Q))2=(1−1/κ(Q)+12)2
右边是 gradient descent 的目标函数收敛速率的一个上界,可以看到
Q
的 condition number 越小,上界就越小,也就是收敛速度会越快。注意到
Q=XTX+λI,通过特征值的定义即可简单验证,假设
XTX
的 condition number 是
L′/l′
的话,加上 regularizer 之后它的 condition number 变为
(L′+λ)/(l′+λ),会变小,从而改善收敛速度。
虽然这只是收敛速度的一个 upper bound,但是 condition number
对实际的收敛速度影响还是蛮大的,图
(fig:
1) 给出了两个不同的 condition number 的情况。
为了让图好看一点,我给图中的横纵坐标用了不同的比例,所以不太看得出来
exact line search 下 gradient descent
的一个性质:前后两次迭代的移动方向是正交的。注意到第
k
次迭代是沿着
−∇f(xk)
的方向移动
tk
使得
qk(t)
最小,因此
0=qk′(tk)=dtdf(xk−t∇f(xk))t=tk=−⟨∇f(xk),∇f(xk+1)⟩
所以如果横纵坐标轴的比例一样的话,收敛路径应该看起来是正交的 zig-zag
形状。实际中如果
q(t)
比较复杂不能直接优化的话,由于是一元函数,可以用一个通用的二分查找法来寻找
q′(t)=0
的点。
上面是针对一个 quadratic 函数来进行的具体分析,对于我们刚才讨论过的
general 的函数
f
并且其 Hessian 满足
lI⪯H(x)⪯LI
时,L/l
作为其 Hessian 的 condition number 的一个上界同样会以类似的方式影响
gradient descent 的收敛速度。例如可以参考《Convex
Optimization》里的 9.3.1 节。
接下来我们再来看一个复杂一点的 Logistic Regression (LR) 的例子。LR 是
machine learning
中的一个经典的分类算法,虽然挂着“Regression”的名号,但是确实如假包换的
classification 算法。LR 的基本假设是数据类别间是由一个线性的 decision
boundary 隔开的,换句话说
logP(y=−1∣x)P(y=+1∣x)=wTx
再结合
P(y=+1∣x)+P(y=−1∣x)=1
可以解得:
P(y=+1∣x)P(y=−1∣x)=1+exp(wTx)exp(wTx)=1+exp(−wTx)1=1+exp(wTx)1⎭⎬⎫=1+exp(−ywTx)1(2)
在 training data 上进行 maximum log-likelihood 参数估计是
wmaxlogi=1∏NP(yi∣xi)=wmin−i=1∑Nlog1+exp(−yiwTxi)1=wmini=1∑Nlog(1+exp(−yiwTxi))(3)
这个 binary 的情况所具有的特殊形式还可以从另一个角度来解释:先抛开
LR,直接考虑 Empirical Risk Minimization (ERM)
的训练规则,也就是最小化分类器在训练数据上的 error:
E=i=1∑N1{yi=sign(f(xi))}=i=1∑N1{yif(xi)≤0}
但是这是个离散的目标函数优化非常困难,所以我们寻求函数
1(⋅≤0)
的一个 upper bound
ℓ(⋅),然后去最小化
E′=i=1∑Nℓ(yif(xi))
当取
ℓ(x)=log(1+exp(−x))
(该函数通常称作 log
loss)时,即得到同
(eq:
3) 一样的式子,也就是 LR 的目标函数,并且我们接下来会看到,这个 ERM
的 upper bound 是易于优化的。顺便提一句,通过选择其他的 upper
bound,我们会导出其他一些常见的算法,例如 Hinge Loss 对应 SVM、exp-loss
对应 Boosting。注意到 log loss 是 convex 的,有时候我们还会加上一个
regularizer
L(w)=E′(w)+1/2λ∥w∥2
此时目标函数是
λ-strongly
convex 的。接下来我们考虑用 gradient descent
来对目标函数进行优化。首先其 Gradient 是
∇L(w)=i=1∑N−1+exp(−yiwTxi)exp(−yiwTxi)yixi+λw
其中
Pw(y∣x)
由式
(eq:
2) 给出。这里我们使用 Wolfe’s Condition 来选择 step size。Wolfe’s
Condition 有两个参数
0<m1<m2<1,设
pk
是移动方向(并不一定是
−∇f(xk)):
- f(xk+tpk)≤f(xk)+m1t⟨∇f(xk),pk⟩,亦即
q(t)≤q(0)+m1tq′(0)
- ⟨∇f(xk+tpk),pk⟩≥m2⟨∇f(xk),pk⟩,亦即
q′(t)≥m2q′(0)
可以证明当
f
连续可导并且有下界时,一定存在一个区间内的步长都满足 Wolfe’s
Condition。并进而可以证明按照 Wolfe’s Condition 选择步长的算法在
gradient 是 Lipschitz 连续并且移动方向和 gradient
的负方向不会偏离太远的话,可以保证算法收敛到一个 stationary
point,详见《Numerical
Optimization: Theoretical and Practical Aspects》引理 3.8 和定理
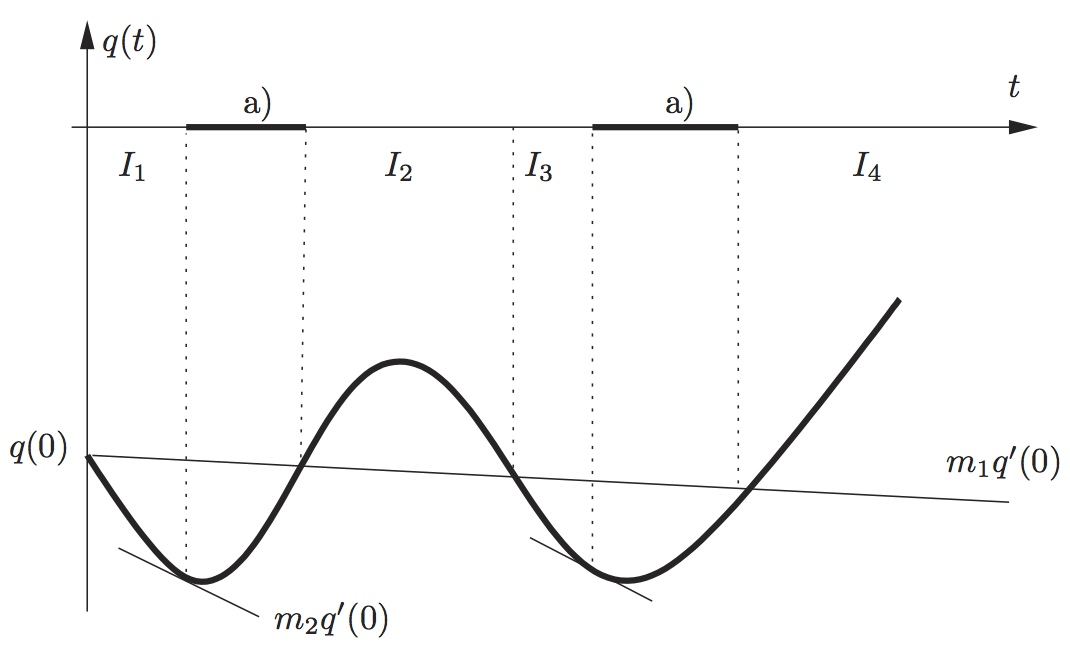
3.9,顺便盗一张图来说明一下:
第一个条件主要是用来限制步长不能太大,因为除非
q(t)
随着
t
增长无下界,否则一定存在
t′
使得所有
t>t′
都不能满足第一条。第二条则限制步长不要太短,因为如果步长衰减太快的话可能就没法收敛到
stationary point 了,因为
pk
是是下降方向(和 gradient 成钝角),所以
q′(0)<0,exact
line search 是要找到
q′(t)=0
的点,而这里只要求
q′(t)≥m2q′(0)
就可以了。图中两段黑色的区间是满足 Wolfe’s Condition 的步长。
下面的 Julia 代码示例了用二分法搜索满足 Wolfe’s Condition
的步长的算法,简单来说就是,如果不满足第一条,则减小步长;不满足第二条则增加步长。
- function linesearch{T}(p::OptimizationProblem,
- x::Vector{T}, d::Vector{T})
- low = convert(T, 0)
- high = inf(T)
- t = convert(T, t0)
- fx = objval(p, x)
- dfx = gradient(p, x)
- while true
- if objval(p, x + t*d) > fx + c1*t*dot(dfx, d)
- high = t
- t = (low + high) / 2
- elseif dot(gradient(p, x+t*d), d) < c2*dot(dfx, d)
- low = t
- if isinf(high)
- t = 2*low
- else
- t = (low+high)/2
- end
- else
- break
- end
- if high-low < tol
- break
- end
- end
- return t
- end
再回到 LR,我们可以直接套用上面的算法进行步长搜索。我们用 USPS
手写数字识别数据集上的分类作为示例。由于我们刚才推导的是简单的两类
LR 算法,所以我们只简单地示例手写数字 1 和 2
之间的分类:我们随机地将数据平均分为 training 和 testing 两部分,图
(fig:
2) 为在 training data 上跑 gradient descent
的收敛曲线。由于我们是按照 log-scale 来画 y
轴的,所以可以看到在前几次迭代之后就进入比较稳定的线性收敛趋势中。
LR 的分类非常简单,只要计算
sign(wTx)
即可,如果希望得到具体的 conditional probability 的话,可以按照
(eq:
2) 来计算概率。在 USPS 上数字 1 和 2
的分类问题中我们通过随机初始化的 gradient descent 训练出来的 LR
模型在测试数据上的精确度平均都在 99% 以上。



Comments
不错,convex那本书关于用Hessian Matrix的范数的上下界对于优化算法分析很不错
恩,我也是前两天才发现,以前看 Boyd 那本书都只看到第五章就没看下去了。
关于你的julia,我好奇这样一个问题:
你的julia的矩阵运算相关用的是 julia自己下载的blas和lapack,还是自己系统上的blas和lapack,还是MKL库?
我用的是 Mac 下的预编译版本,打包成一个 .app 的,并没有自己另外专门下载 MKL 。
看了你的blog,内容不错。风格样式做的也真心喜欢,用什么做的?
光用Pandoc做不出这种效果吧,自己订制的多吗?
你好,是用 pandoc 套上 liquid template 再加一点自己山寨的扩展做成的。
如果是二次的目标函数那就用共轭梯度法或者牛顿法,一步到位妈妈放心
https://class.stanford.edu/... 新版的Convex课开课了,不过比较紧
恩,我也看到了。
kid 我有一个疑问 既然通常optimization找到的是stationary point 为啥大家都在paper里面claim找到了 local optimum? 是不是很有可能想找到的不是minimum而是maximum或者反过来?
可能有些并不是专门研究优化问题的 paper 的话,对这个问题也许模糊一点说也没有关系,就好像很多 paper 很模糊地说某些问题是 NP 或者 NP hard 之类的一样。
一般如果是找到 gradient 等于 0 的点的话,只能说是一个 stationary point,但是在 practice 中,比如如果本身使用的是 descent 的方法保证每一步 objective function 都下降的话,那么至少不会是个 maximum 点(除非是一步收敛或者 objective function 只是保持“不增加”而已)。另外的可能就是碰到既非 maximum 也非 minimum 的点,比如像 x^3 在 x=0 处这样的,通常这样的 stationary point 在数值上并不稳定,我感觉收敛到这样的点的几率也不是很大的样子。所以如果重点不是在于优化算法的研究的话,在实际中那样 claim 应该也不算太离谱。
赞, 了解了 多谢!
pluskid,您好!经常浏览您的blog,从中学到了很多知识,非常喜欢。
不知能不能向您请教一个问题:
我有时在机器学习相关论文中会看到“oracle”这个词,不知该作何理解?比如您在“Machine Learning and Optimization”中也曾提到“于是(机器学习方面的)人们逐渐将注意力集中到主要基于 first-order oracle 的单次迭代计算量非常小的算法上”,这里的oracle具体是什么意思呢?谢谢!
oracle 这个英文单词的意思我想你理解,他们说 oracle 主要是想要强调,比如要优化的函数,是一个 blackbox,你不知道其具体的表达式或者结构,只能对你能选择的点进行函数值(和、或一阶、二阶导数)进行 “query”,并得到回答,就像你去问一个 oracle 问题,它告诉你答案一样。
哈哈,解决了我的疑惑,英文有些东西也是只可意会,没法翻译
赞一个,没看懂……
弱弱的问一下你的数学公式是用什么方式显示的,我猜写的时候应该是latex吧,但是是怎么在html中显示的?感觉完全没有延时啊,我自己用MathJax,总是要等到页面加载完全之后才能进行渲染,体验不是很好。
我也是用的 MathJax,不过先在 server 端把它渲染出来转换成 svg 图片了,用 svgtex 可以转:https://github.com/agrbin/s...
pluskid你好,我有一个地方没有理解。
当你在eq:3之后考虑ERM的时候,y不等于sign(f(x))的下一步是否写成yf(x)<=0?而不是>=0. 也许是我理解错了,另外这个1(.>=0)的函数为什么能被logstic(.)给uppper bound住呢?谢谢 ;-)
你的博客很有帮助!潜水很久了哈哈哈。。
啊!你好,非常感谢发现这个错误,确实是写错了哈!刚刚改过来,然后关于 upper bound 的问题,实际上要用以 2 为底的对数才能得到严格的 upper bound,也就是全局缩放一下,不过全局缩放不影响最优解,所以在实际计算的时候方便起见仍然使用自然对数。这个我也加了一段说明。
试试能不能写公式$$x^y$$
\(x^y\)
目前并没有在评论中启用公式支持。
不好意思刷屏了好像删不掉。不知道怎么打公式讲不清楚,我就又算了会,现在自己搞清楚了。非常感谢!
看了你的博客,觉得统计专业想学机器学习或数据挖掘真是压力很大啊,感觉需要自学很多编程的内容才行……
写得很好,期待下一集!!
博主你好,我是Liu Song在新加坡的朋友,听他提到你,才知道你的blog。
写的非常棒,我这个优化的外行也看懂了大概。
我的问题是,你说对参数的L2 regularization让目标函数变成了 lambda-strong convex的。如果我把L2变成L1 regularization, 就不是strong convex了吧?这时有啥方法保证收敛速度吗?
我这个问题估计优化的paper讨论过了,只是我看的太少了,所以在这里提出来 :) 也希望你给个pointer. 多谢多谢
你好,l1 regularization 不能保证 strong convex。不过 complexity analysis 这个东西就作为一个参考,也不能完全迷信了。首先它是针对某一种具体的算法,比如固定步长或者某种 line search 下的 gradient descent 之类的,不同的问题可能会有其特殊的结构然后有对应的快速解法也不一定;其次这些复杂度大部分情况下都是一个 upper bound,并不一定就是 tight 的 bound。
楼主有个地方可能是不小心写错了.
"此外, H <= LI 的条件可以理解为在说 gradient 的 Lipschitz 连续性,实际上它等价于说 f 的 strong convexity。"
H <= LI 是在说 gradient 的 Lipschitz 连续性,
H >= mI (小写l看不清楚换成m) 才是在说 f 的 strong convexity,
这两个性质不是等价的,而是有些相反的,前者能导出凸函数 f 的 quadratic upper bound ,后者能导出 f 的 quadratic lower bound。
嗯,确实是!谢谢指出,我修正了一下!
楼主,要是有个具体的示例相结合那就更完美了。
我最近也在研究LR中的line search,我有一个疑问,比如我有m个训练样本,根据Wolfe condition,求步长时必然要反复带入不同的尝试值计算q(t)和q'(t),但是LR中q(t)时间复杂度至少是O(m)(要算log-likehood function),而q'(t)中时间复杂度至少是O(m * n)。这样就会让line search寻找步长这个代码变得很耗时。在实践中这个问题你是怎么处理的?
在逻辑回归哪里是不是有错 ,y=-1和y=1的情况怎能直接就用在后面的wx中呢,他们是计算y=1的时候的概率的啊 不能直接带入进去的吧,